
Morphのサンプルワークスペースを見ながらプロジェクトや設定の関係性を読み解く
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
しんやです。
下記のエントリでは『Morphってそもそも何なんだ?』という内容を紹介しました。
当エントリではMorphのワークスペースにおける各種ファイルの構造や関係性がどのようになっているのかについて、公式情報を参考に読み解いていきたいと思います。
ワークスペース設定ファイル探索
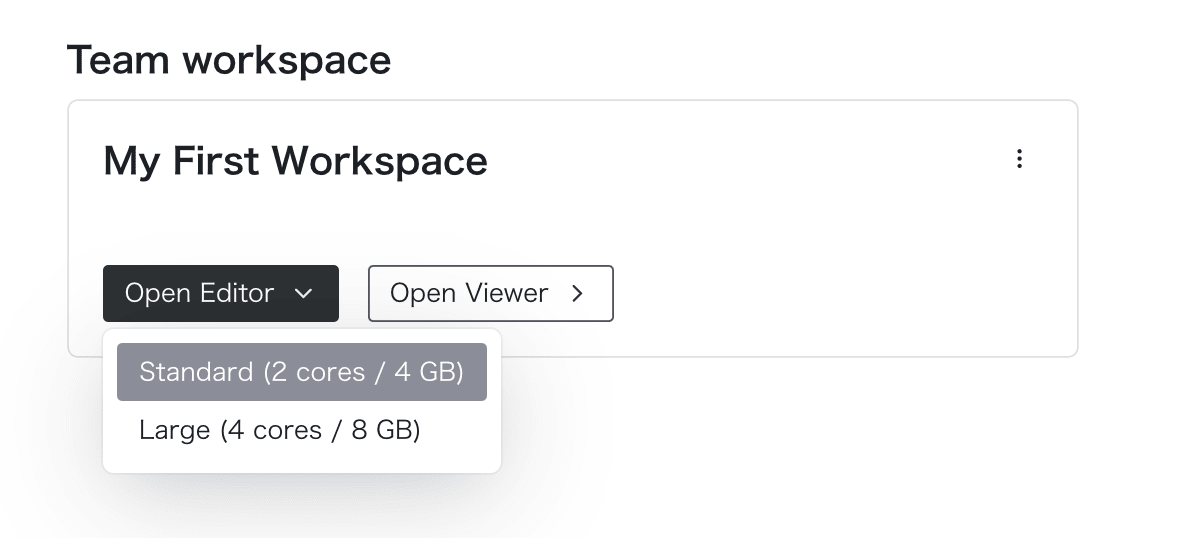
参考となるプロジェクトは前述ブログエントリで言及&Morphアカウント作成時点で既に用意されているワークスペース『My First Workspace』を用います。
ワークスペースを選択し、[Open Editor]モードでアクセス。
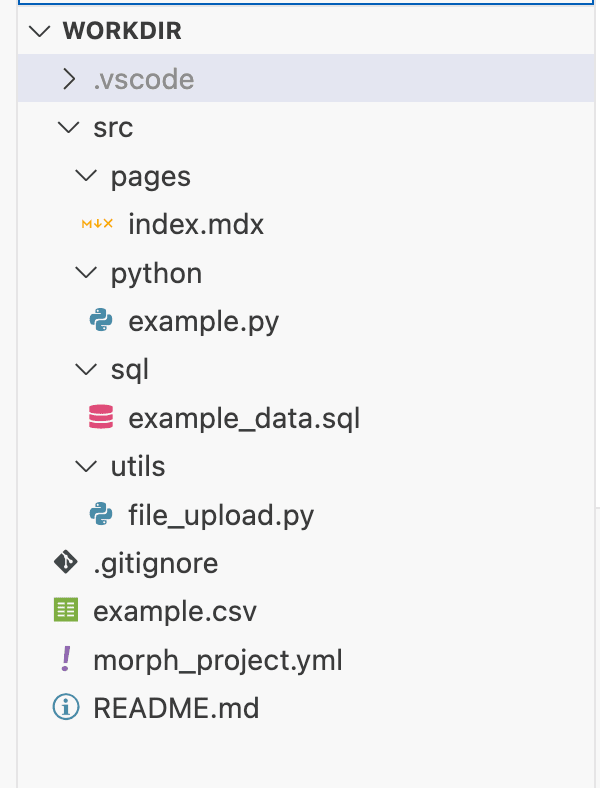
編集(Editor)モードで閲覧可能なエクスプローラメニューで表示されている下記のファイル群についてそれぞれ見ていきます。
morph_project.yml
まず初めに見るのはMorphワークスペースの基本的設定を司る設定ファイル: morph_project.yml。
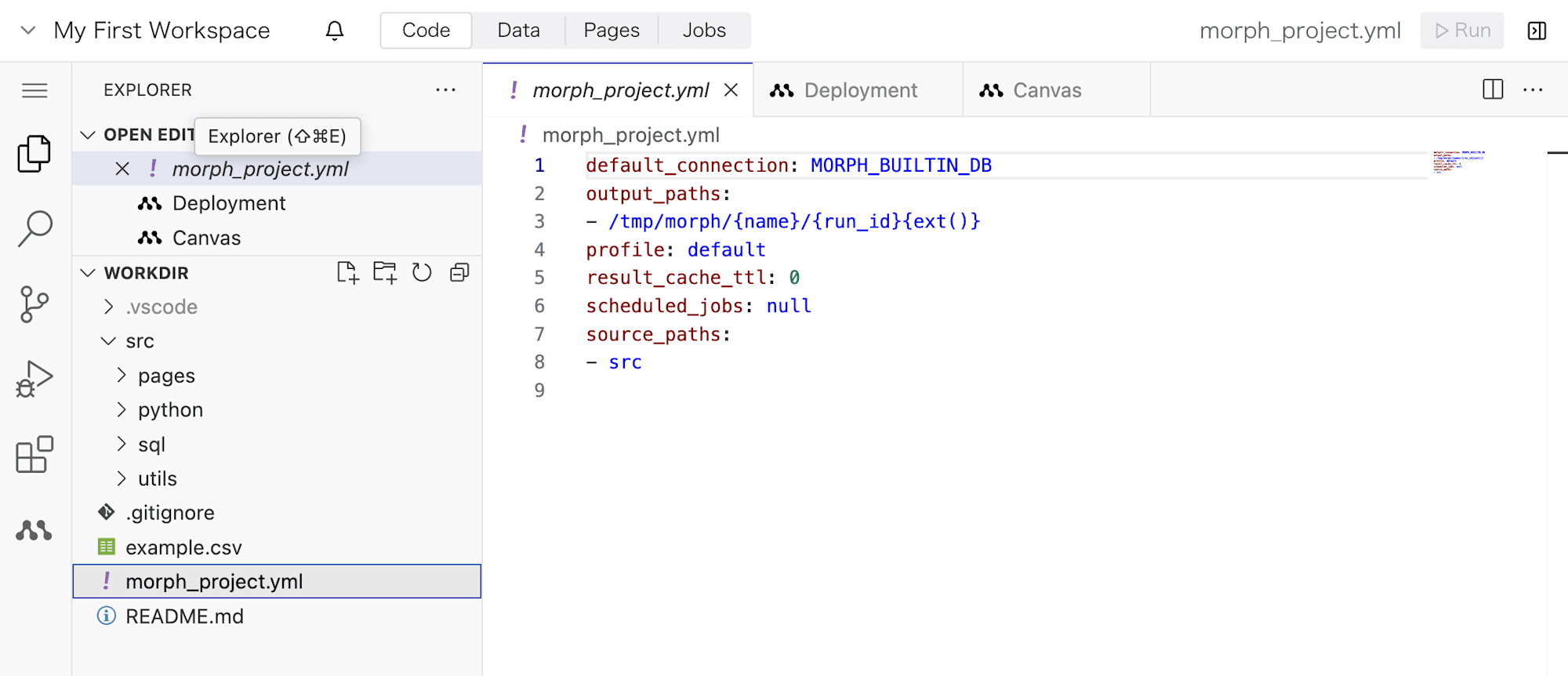
ワークスペース作成直後の内容は以下のようになっています。
default_connection: MORPH_BUILTIN_DB
output_paths:
- /tmp/morph/{name}/{run_id}{ext()}
profile: default
result_cache_ttl: 0
scheduled_jobs: null
source_paths:
- src
設定リファレンスは下記ドキュメントをご参照ください。
この設定ファイルでは以下の内容を設定可能です。
default_connection
- ワークスペースがデフォルトで接続しに行く接続情報
- SQLファイルでconfig関数の中でconnectionを指定しなかった場合は自動的にこの接続が使用される
DUCKDB、MORPH_BUILTIN_DBはコネクションを作成せずとも使える- 気になった点:
- 個別に作成した接続を指定する場合はどういった名称を指定する必要がある?(コネクション作成メニューで指定した接続名を用いるとかになるのかな?【要確認】
output_paths
- データパイプラインの実行結果が保存される場所
- データパイプラインの実行結果とは?
- 実行結果は生成されたSQLやPythonコードの出力で、データの変換や処理の結果が含まれる。
- 参考:データパイプライン構築 - Docs
設定方法詳細は下記ドキュメントを参照。
profile
- ドキュメントには言及無し、何だろこれ?【要確認】
result_cache_ttl
- データパイプラインの実行結果のキャッシュの有効期限を秒単位で指定可能。
- 初期値は0。実利用の際には負荷軽減のために任意の値を設定しておいても良さそう。
scheduled_jobs
- スケジュール実行の設定を指定可能。
- 初期値はnullとなっており、特に設定されているものは無い。
- 公式ドキュメントには以下のような形で記載がある。この辺りも実利用が見込まれる場合は所定のサイクルで実行するように記載をしておきたい。
# Scheduled Jobs
scheduled_jobs:
function_name_1:
schedules:
- cron: "cron(0 0 * * 1,3,5)"
is_enabled: true
timezone: "Asia/Tokyo"
variables:
priority: "high"
retry: 3
- cron: "cron(0 12 * * 2)"
is_enabled: false
timezone: "UTC"
variables:
notify: true
email: "alert@example.com"
function_name_2:
schedules:
- cron: "cron(0 18 * * 6)"
is_enabled: true
timezone: "Europe/London"
variables:
type: "maintenance"
duration: "2h"
設定方法詳細は下記ドキュメントを参照。
source_paths
- ここで指定したディレクトリ配下にあるファイルがMorph上で実行可能なソースコードとして扱われる。
- デフォルトは
src。エクスプローラー上ではこの部分が該当。
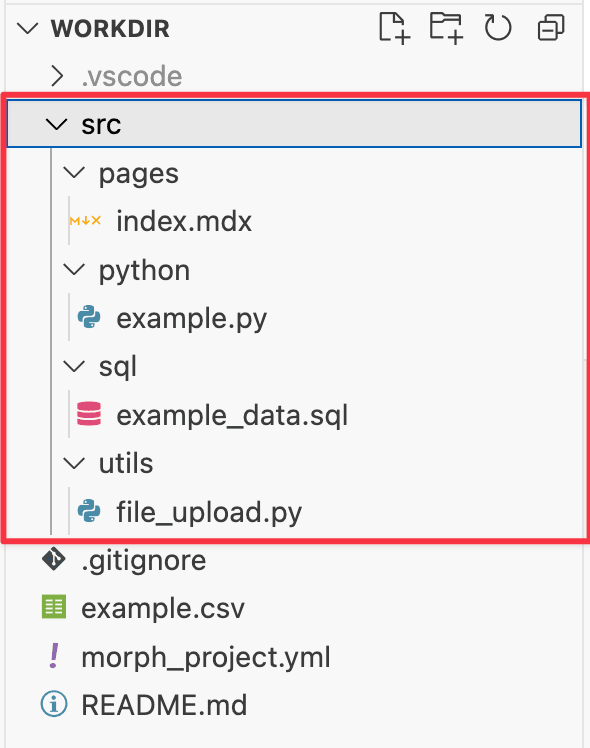
source_path配下の構成ファイル
データアプリケーション表示ページ(pages/index.mdx)
Morphアプリケーションを起動、アクセスした時に最初に見ることになるアプリケーションページ。pages/ディレクトリ配下に拡張子mdxでファイルを作成しているようです。ページを追加する際もpages/ディレクトリ配下に任意の階層やページを追加するで行けそう。
こういう記載内容だと、
export const title = "GA App";
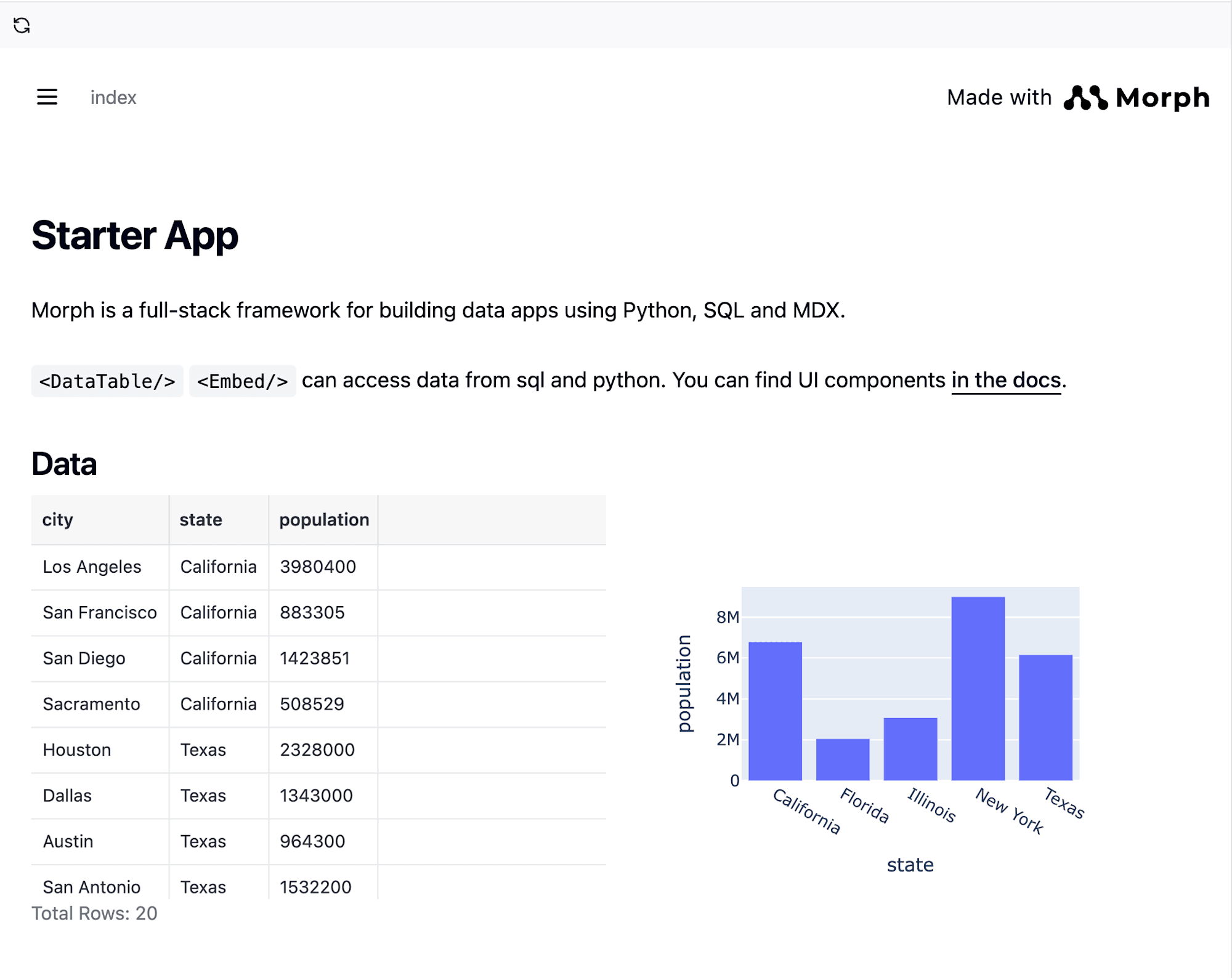
# Starter App
Morph is a full-stack framework for building data apps using Python, SQL and MDX.
`<DataTable/>` `<Embed/>` can access data from sql and python.
You can find UI components [in the docs](https://docs.morph-data.io).
## Data
<Grid cols="2">
<div>
<DataTable loadData="example_data" height={300} />
</div>
<div>
<Embed loadData="example_chart" height={300} />
</div>
</Grid>
このように表示されます。
データアプリケーションページ及びページ配下で実装することになるパーツそれぞれを作るための『コンポーネント』に関する除法は下記ドキュメントを参照。
その他mdxファイルに関する情報は下記ドキュメントを参照。
気になったこと:
- ワークスペースでは棒グラフを表示していたが、グラフの表示形式の制御はどこでやるの?index.mdxファイルにはその記載は見当たらなかった。
- 【自己解決】後述するPythonファイルやSQLファイルで記載した処理内で定義している情報をmdxファイル側で指定することにより処理を実現している。(データコンポーネント:
<DataTable/>、<Embed/>、<Metrics/>共にその形を取っていることを確認出来た)
- 【自己解決】後述するPythonファイルやSQLファイルで記載した処理内で定義している情報をmdxファイル側で指定することにより処理を実現している。(データコンポーネント:
Python実行内容
src/pythonディレクトリ配下のPythonプログラム:ワークスペース作成初期段階だとsrc/python/example.pyが該当。所定のコネクションからデータを取得し、アプリケーションページで表示するためのデータをPythonコードで編集・加工している。
import plotly.express as px
import morph
from morph import MorphGlobalContext
@morph.func
@morph.load_data("example_data")
def example_chart(context: MorphGlobalContext):
df = context.data["example_data"].groupby("state").sum(["population"]).reset_index()
fig = px.bar(df, x="state", y="population")
return fig
Pythonプログラム記述に関する情報については下記ドキュメント群を参照。
SQL実行内容
src/sqlディレクトリ配下のPythonプログラム:ワークスペース作成初期段階だとsrc/sql/example_data.sqlが該当。所定のコネクションからデータを取得し、アプリケーションページで表示するためのデータをSQLコードで編集・加工している。
{{
config(
name = "example_data",
connection = "DUCKDB"
)
}}
select
*
from
read_csv("example.csv")
Pythonプログラム記述に関する情報については下記ドキュメント群を参照。
ユーティリティプログラム格納ディレクトリ(utils)
ワークスペース配下にはutils/ディレクトリが存在していました。配下にはfile_upload.pyというプログラムが格納されています。
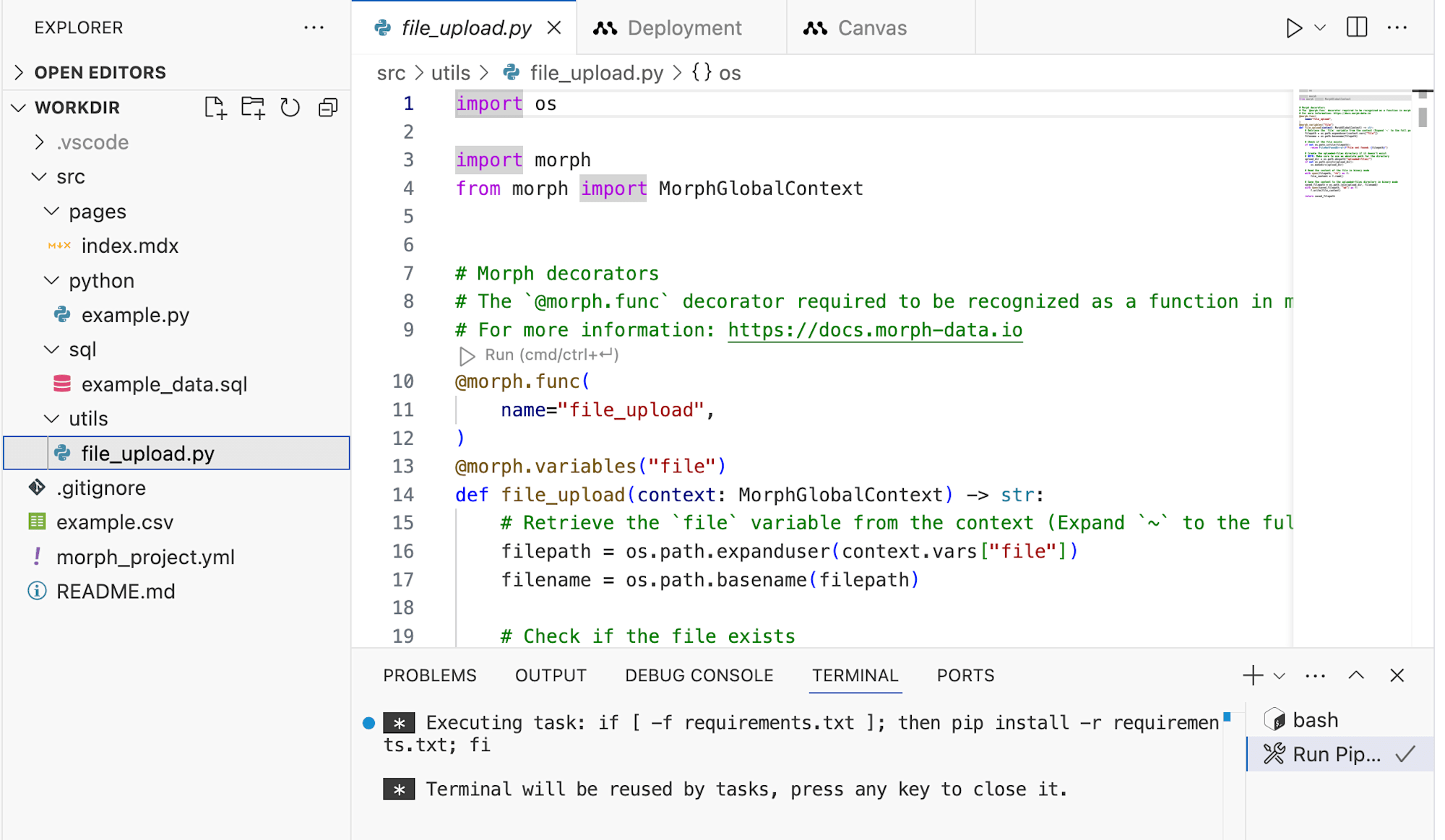
Morphプロジェクトにおいて、utilsディレクトリは一般的に、共通で使用するユーティリティ関数やヘルパー関数を格納するために使用されます。このディレクトリを活用することで、コードの再利用性を高め、プロジェクト全体のコードをよりモジュール化し整理することができます。
『ファイルアップロード』という文言で気になったのは以下の機能。MorphにはサービスにCSVやExcelをアップロードする機能があり、データベースやデータウェアハウスを介さずともデータ加工・可視化が簡単に試せる!という代物らしいが、ワークスペース上のCanvasからはそういったメニューが見当たりませんでした。編集(Editor)モード以外の場所から辿れる機能なのでしょうか。ここは追々確認出来たら試してみたいと思います。
サンプルCSVファイル(example.csv)
ワークスペース直下に格納されているCSVファイル。データアプリケーションページでもこのファイルを使って
SQLファイルでCSVファイルを読んでいる。この部分の流れがいまいち掴めていない。こういう理解で合っているのかな?【要確認】
- 機能を使ってCSV/Excelファイルをアップロード
- アップロードされたファイルはアプリケーション内のDB(DUCKDB)に所定の内容で格納される
- SQLを書く際に"所定の記法"で書くことで、CSVファイルをSQLを介して検索出来る
{{
config(
name = "example_data",
connection = "DUCKDB"
)
}}
select
*
from
read_csv("example.csv")
まとめ
という訳で、Morphワークスペースのお作法的なもの、構成情報の理解を深べるべく、自分なりに理解咀嚼した内容を備忘録的にまとめてみました。【要確認】の部分については引き続き調査していく予定です。情報が判明したいアップデートしていきたいと思います。このエントリが読者の皆さんの何らかの一助になれば幸いです。






